Detailed :: DocHelper
The image accompanying this text is intended to describe the general architecture of DocHelper. In the Image light blue represents an interface, blue an concrete class and dark grey a class that has not been implemented yet.
Containment can mean a has a relationship, if a concrete class is the container or a
is a (implements) relationship if an interface is the container.
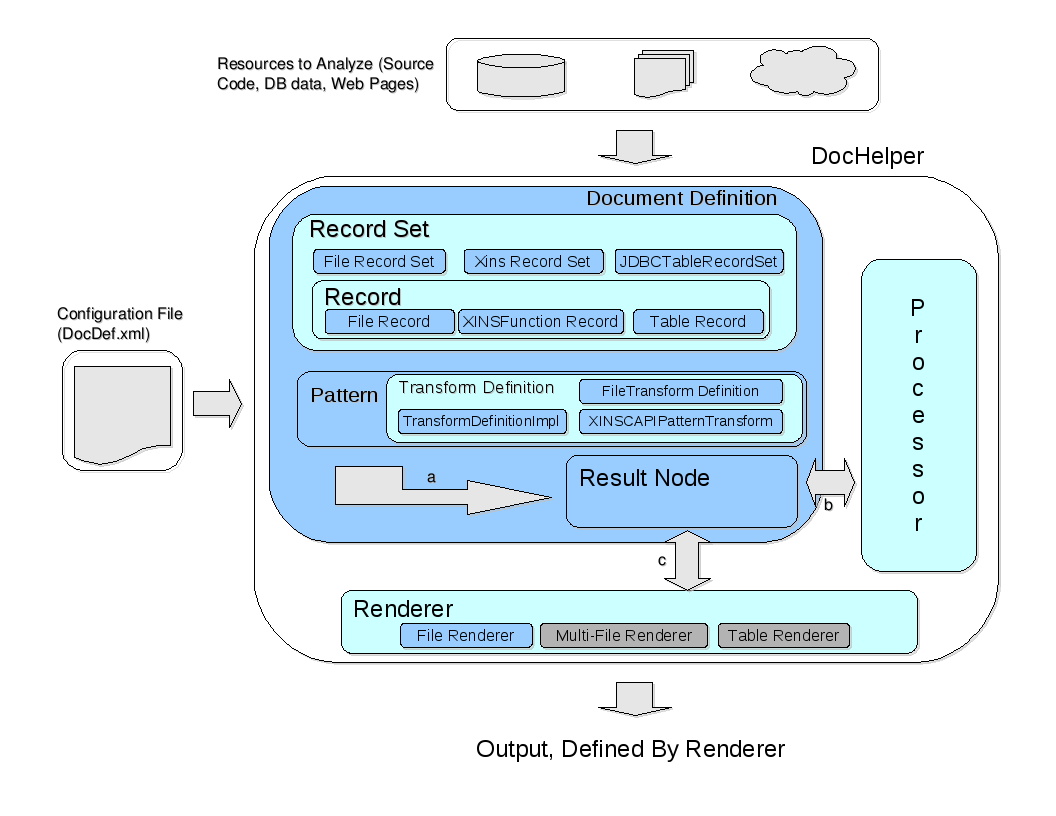
The image also makes note of three main steps within the DocHelper process (a, b, c) and how they are implemented by the architecture.
Steps
A.)
Given a valid DocHelper configuration file, when DocHelper is run the result is a ResultNode tree. The result tree is contained within DocHelper literaly: as a composition relationship to a ResultNode object (the root of the tree).
B.)
Once executed the result tree may be modified through the application of one or more processors at different levels of the tree. These processors and their application points are defined within the configuration file. The processor may perform any operation on the tree: is has the freedom to completley alter tree structure. Currently there are two processors, both for sorting results (one based on matched values, the other based on node parameters).
C.)
After all processors have run, DocHelper will execute any Renderers associated to this document definition, also specified in the configuration file. These renderers turn the (processed?) result tree, its matches after transformation by specific pattern transform definitions, and its structure into various forms of output. Currently there is only one renderer creates a file based on the result tree.
Architecture Explanation
DocHelper works based on a configuration file. The usual name has been DocDef.xml, however the name can be anything. The full bath to the configuration file is passed as a String parameter to the entry point of DocHelper (the static method execute(String configurationFile) id class DocHelper ). If executed from the command line, the path to this file is passed a command line argument.
When executed, DocHelper will create a DocumentDefinition object per <documentdef> section in the configuration file. The DocumentDefinition object is made by parsing the configuration file. When parsing the file, all supporting objects are created before the DocumentDefinition object is made. This means that any processors or renderers referenced will be created and placed in a list of available, Processors or Renderers. The created DocumentDefinition object will contain references to RecordSets. RecordSet is an interface providing an easy access point for extension for users. A new recordset that reads resources in a specific way for a user can be created by imlementing the RecordSet interface. The new RecordSet may be reference using the class attribute of the <RecordSet> tag. Whitout any change to the dochelper library the user should be able to utilize dochelper to analyze new resources.
Each RecordSet should have Records. Record is also an interface. In terms of architecture this interface is only a suggestion as there is no specific restriction placed on the RecordSet interface that requires it to use Records. Essentially RecordSets may do anything as long as they are able to produce a result tree (ResultNode) and are configurable. All implemented RecordSets currently use the Record interfce and it is recommended they do, as the Record interface provides a clear and easy to use template as to how to deal with elements in a RecordSet.
A recordset reference may be "attached" to pattern references. Each <pattern> tag defines one specific expression to search for and how its matches should be transformed into content. Since patterns may be universal to a problem set, they are created independently of the DocumentDefinition but may be reference by recordsets within the document definition. Each pattern will have a composition relationship with a TransformDefinition. The TransformDefinition is also an interface and it specifies the methos that a class needs to imlement in order to transform a match into content. There a 3 implementations of this interface that allow the transformation to be provided directly in the XML or through a template file. In the same manner that a new RecordSet class may be created, a TransformDefinition imlementor may be created and referenced using the class attribute of the <transform> tag. This flexibility is provided so that a user can transform a regular expression match in any way he wishes to. Any number of patterns may be referenced by a recordset. A Pattern can only have a single transform definition.
A DocumentDefinition may also reference processors to modify the result tree once resources have been searched and transformations by <transform> definitions have been made. These processor are called in the order they are found but may affect different parts of the result tree, leaving others untouched. A reference to a processor can be placed for the entire document, only for a record set or only for a particular pattern. Depending on where in the configuration XML the definition is placed, the processor will affect certain areas of the result tree. The processor is again an interface and may be implemented outside the dochelper package in order to provide extended ways to process result trees. The same mechanism of using class attribute of the <processor> tag is used here. In all these cases it is important to remember that the class specified within any class attibute of the DocHelper configuration file must be available in the runtime class path.
The ResultNode object is the main building block of the results tree. It describes the outcome of searching for the referenced patterns in each of the referenced recordsets and transforming the matches according to the transform
definitions of each pattern. As with many other trees the structure of the tree has significance.
The first node represents the DocumentDefinition it self, is has no value since nothing in the DocumentDefinition it self can be matched.
The children of this node each represent RecordSets, again no value, only children (i.e. Records) that may have matches. The next level (3) of nodes are Records, each of these are Records within a RecordSet. Again no value,
a record it self does not have direct matches, each record has patterns that may have had matches. As you can guess, the next level of the tree are Patterns, no direct value as each match of the pattern within a record is a child of this
node. The final nodes (lead nodes) are the matches themselves, they have no children but do contain the transformed value- The match transformed into content by applying the transform definition specified for the pattern in question.
Currently there are processors that can modify the tree (sort) based on value (the transformed match) or on the params of each node (for eaxmple filename for a FileRecord). We may wish to analyze * set of files and then order the tree so when rendering the files analyzed are sorted by name, or size or some other value that is available to this type of Configurable (Record or RecordSet).
So this takes us to the second mention of a Configurable. The Configurable interface is the Parent Interface of RecordSet, Processor and Renderer. It referes to an object that can be defined in the configuration file that may be setup through the use of the <params> tag. These objects may be given name value pairs, marked up as <param>'s to provide an object with additional and flexible information that may vary from object type(class) to object type. It is impossible to define all of the possible intialization parameters that a recordset or Processor may have at compilation time, given the the class for these object may be defined through the configuration file. For configurables, the paraeters that have been passed are stored within a params hashtable that hold these for later use. For flexibility during rendering and processing a copy of the parameters has been created for each ResultNode.
If ResultNode A desribes a FileRecord within a certain RecordSet, and the file record has a params Map holding [filename->out.html, filepath->/home, extension->html], then the ResultNode will have a copy of this Map. Later on this copy may be used when processing or rendering the tree: for example if a user wishes to sort the tree by filename. (For this the NaturalOrderParamProcessor can be used).
These parameters can be used when rendering the tree as well. Renderers are the final part of the discussion. As the name suggests, they are in charge of creating output based on the ResultTree. Once more, Renderer is an interface and the renderer type can be defined using the <Renderer> tag's class attribute. The renderer is tasked with creating actual output for the ResultNode based on the transform and on encapsulating content. The idea is that a <Renderer> section may define diferent document sections for each of the items in a DocumentDefintion.
A docsection defines start and end sections as strings that can be prepended or appended to each section of the document. For example a document section that is applied to the overall document definition can define the header and footer of an
entire document. A <docsection> defined for a particular recordset will wrap results from the recordset in start and end section defined within it. It is important to know that a document section may reference and param available to it. The params
available to it are directly related to what section of a tree it is applied to. Following the example from above, if a document section is defined for FileRecord within a certain record set, it will have access to the
[filename->out.html, filepath->/home, extension->html] map. Both the start and the end of the document sections are Strings: "This is the begining of the document".
They can reference a param within the corresponding ResultNode by prepending the paramname with a dollar sign, as in:
"File $filename in $filepath has the following matches: ".
Documement sections can be defined in the configuration file literally or using the file attribute.
For a Document more than one renderer can be applied creating different input simultaneously for the same set of resources. Both a flat file and a PDF may be created for the same input for example.
Useful links: